이론(2) - Web Browser
1. Background: Web Browser
1-1. 웹 브라우저
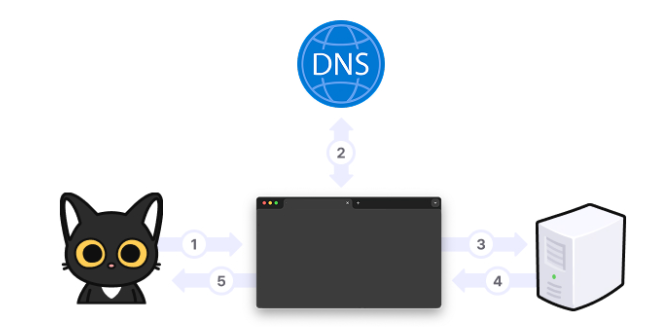 1. 웹 브라우저의 주소창에 입력된 주소를 해석 ( URL 분석 )
1. 웹 브라우저의 주소창에 입력된 주소를 해석 ( URL 분석 )
2. 해당하는 주소 탐색( DNS 요청 )
3. HTTP를 통해 해당 주소에 요청
4. 해당 주소의 HTTP 응답 수신
5. 리소스 다운로드 및 웹 랜더링( HTML, CSS, Javascript )
최근에는 HTTPS 적용 여부 및 서버 인증서의 안전성 여부를 식별해주는 것이 있다.
1-2. URL
웹에 있는 리소스의 위치를 표현하는 문자열이다. 브라우저로 특정 웹 리소스에 접근할 때는, URL을 사용하여 이를 서버에게 요청한다.
구조는 Scheme, Authority (Userinfo, Host, Port), Path, Query, Fragment 등으로 구성한다.

#Scheme - 웹 서버와 어떤 프로토콜로 통신할지 나타낸다.
#Host - Authority의 일부로, 접속할 웹 서버의 주소에 대한 정보를 가지고 있다.
#Port - Authority의 일부로, 접속할 웹 서버의 포트에 대한 정보를 가지고 있다.
#Path - 접근할 웹 서버의 리소스 경로로 '/'로 구분된다.
#Query - 웹 서버에 전달하는 파라미터이며, URL에서 '?'뒤에 위치한다.
#Fragment - 메인 리소스에 존재하는 서비 리소스를 접근할 때 이를 식별하기 위한 정보를 담고 있다. '#'문자 뒤에 위치한다.
1-3. Domain name
URL 구성 요소 중 Host는 웹 브라우저가 접속할 웹 서버의 주소를 나타낸다. Host는 Domain name, IP address의 값을 가질 수 있다. IP address는 네트워크상에서 통신이 이루어질 때 장치를 식별하기 위해 사용되는 주소이다. 이를 대신애서 도메인을 사용한다.
Domain name을 Host 값으로 이용할 때, 브라우저는 Domain Name Server (DNS)에 Domain name을 질의하고 DNS가 응답한 IP address를 사용한다. 예를 들어, 웹 브라우저에서 http://example.com에 접속할 경우에 DNS에 질의해 얻은 example.com의 IP와 통신한다.
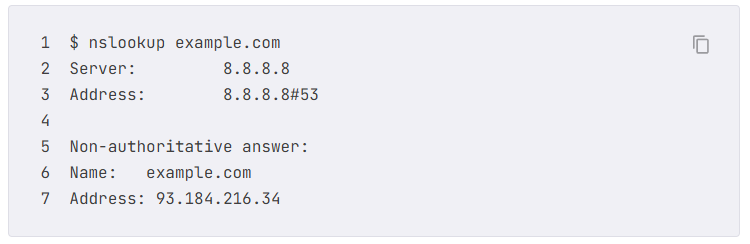
Domain name에 대한 정보는 MacOS/Linux/Windows에서 nslookup 명령어를 사용해 확인할 수 있다.
1-4. 웹 렌더링
서버로부터 받은 리소스를 이용자에게 시각화하는 행위를 말한다.